Over the last few days, I’ve learned that AI infrastructure introduces challenges that traditional applications rarely face:
- GPUs are expensive.
- GPU utilization matters.
- AI workloads often require multiple GPUs at once.
- Scheduling becomes much harder.
That led me to another question:
If Kubernetes already schedules containers, why does Ray exist?
What Kubernetes Does Well Link to heading
Kubernetes is excellent at managing infrastructure.
It answers questions like:
- Which node should this Pod run on?
- How many replicas should exist?
- Is the application healthy?
- Should the workload be restarted?
For example:
User
↓
Kubernetes
↓
Pod
Kubernetes schedules containers.
That’s its job.
The Problem Link to heading
Suppose you want to train a model on a dataset containing millions of records.
The work needs to be split across multiple machines.
Something must decide:
- Which machine gets which data?
- Which worker executes which task?
- What happens if a worker fails?
- How are results collected?
These questions exist above the infrastructure layer.
Kubernetes doesn’t solve them.
Ray Link to heading
Ray is a distributed computing framework.
Instead of scheduling containers, Ray schedules work.
Think of it like this:
Kubernetes → Schedules Infrastructure
Ray → Schedules Computation
This distinction took me a while to understand.
Kubernetes cares about Pods.
Ray cares about tasks and actors.
Ray Architecture Link to heading
A Ray cluster looks like:

The Head Node coordinates execution.
Workers execute tasks.
Kubernetes is often used underneath to manage the infrastructure.
For more details:
Tasks Link to heading
Suppose we have a large dataset.
Instead of processing everything on one machine:
process(data)
Ray can distribute the work:
process.remote(chunk1)
process.remote(chunk2)
process.remote(chunk3)
Each task runs independently.
The work is spread across the cluster.
This enables parallel execution.
Actors Link to heading
Ray also provides something called Actors.
Tasks are stateless.
Actors maintain state.
For example:
| Task | Actor |
|---|---|
| Run | Start |
| Finish | Keep State |
| Disappear | Handle Requests |
| Stay Alive |
This is useful for serving models and building AI applications.
For more details:
Why AI Teams Use Ray Link to heading
Modern AI systems often require:
- Distributed training
- Data processing
- Hyperparameter tuning
- Model serving
- Multi-step AI pipelines
Managing all of this directly with Kubernetes would be difficult.
Ray provides a programming model for distributed computation while Kubernetes manages the infrastructure underneath.
Ray on Kubernetes Link to heading
A deployment looks like:
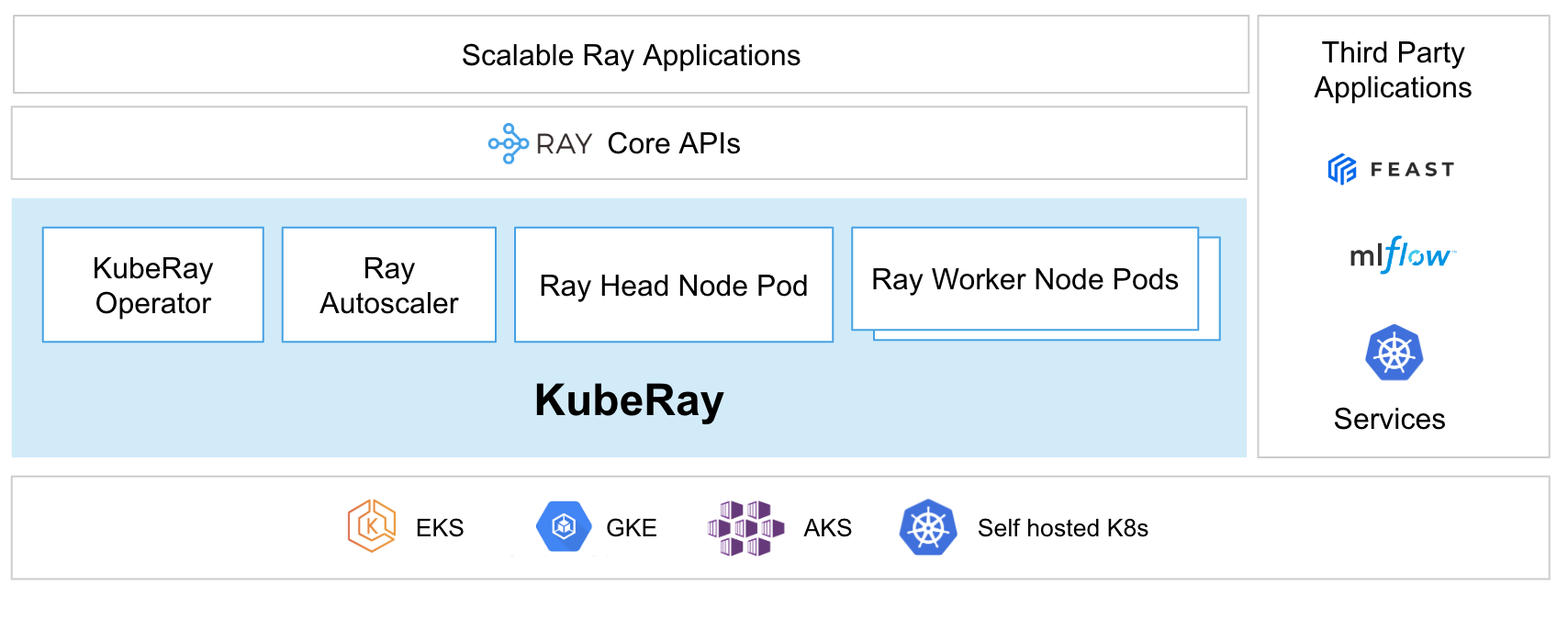
Kubernetes manages the cluster.
Ray manages the workload.
Together they provide both infrastructure management and distributed execution.
For more details:
Today’s Takeaway Link to heading
Before today, I thought Ray was competing with Kubernetes.
It’s not.
They solve different problems.
Kubernetes schedules infrastructure.
Ray schedules computation.
And as AI workloads become more distributed, that distinction becomes increasingly important.
Tomorrow I’ll explore another popular AI infrastructure project:
Why vLLM Exists