Over the last few days, I’ve learned how AI platforms manage GPUs:
- Kubernetes discovers GPUs using Device Plugins.
- GPU utilization is hard.
- Scheduling AI workloads is different.
- Ray distributes computation across a cluster.
That led me to another question:
Why does everyone seem to use vLLM for serving LLMs?
Why not just load a model and expose an API?
The Naive Approach Link to heading
Suppose we deploy an LLM.
The architecture looks simple:
User
↓
Model Server
↓
GPU
A request arrives.
The model generates tokens.
The response is returned.
Problem solved.
Or so I thought.
The Real Problem Link to heading
Imagine 100 users sending requests at the same time.
A naive server processes them independently.
Request 1 → GPU
Request 2 → GPU
Request 3 → GPU
...
This sounds reasonable.
But GPUs are designed for parallel computation.
Running requests one-by-one leaves a lot of GPU capacity unused.
The result:
- Lower throughput
- Higher costs
- Poor GPU utilization
The exact problem I explored on Day 3.
Batching Helps Link to heading
A better approach is batching.
Instead of processing requests individually:
Request 1
Request 2
Request 3
Request 4
↓
Batch
↓
GPU
Now the GPU processes multiple requests together.
Utilization improves significantly.
This is common in many inference systems.
But LLMs introduce another challenge.
The KV Cache Problem Link to heading
When generating text, the model stores information from previous tokens.
This is called the KV Cache.
For long conversations:
- KV Cache grows
- GPU memory usage increases
- Memory fragmentation appears
Soon, memory becomes the bottleneck rather than compute.
This means serving more users isn’t simply a matter of adding batches.
Why vLLM Exists Link to heading
vLLM was built to solve these inference efficiency problems.
Its goal is simple:
Serve more requests with the same GPU.
The key innovation is:
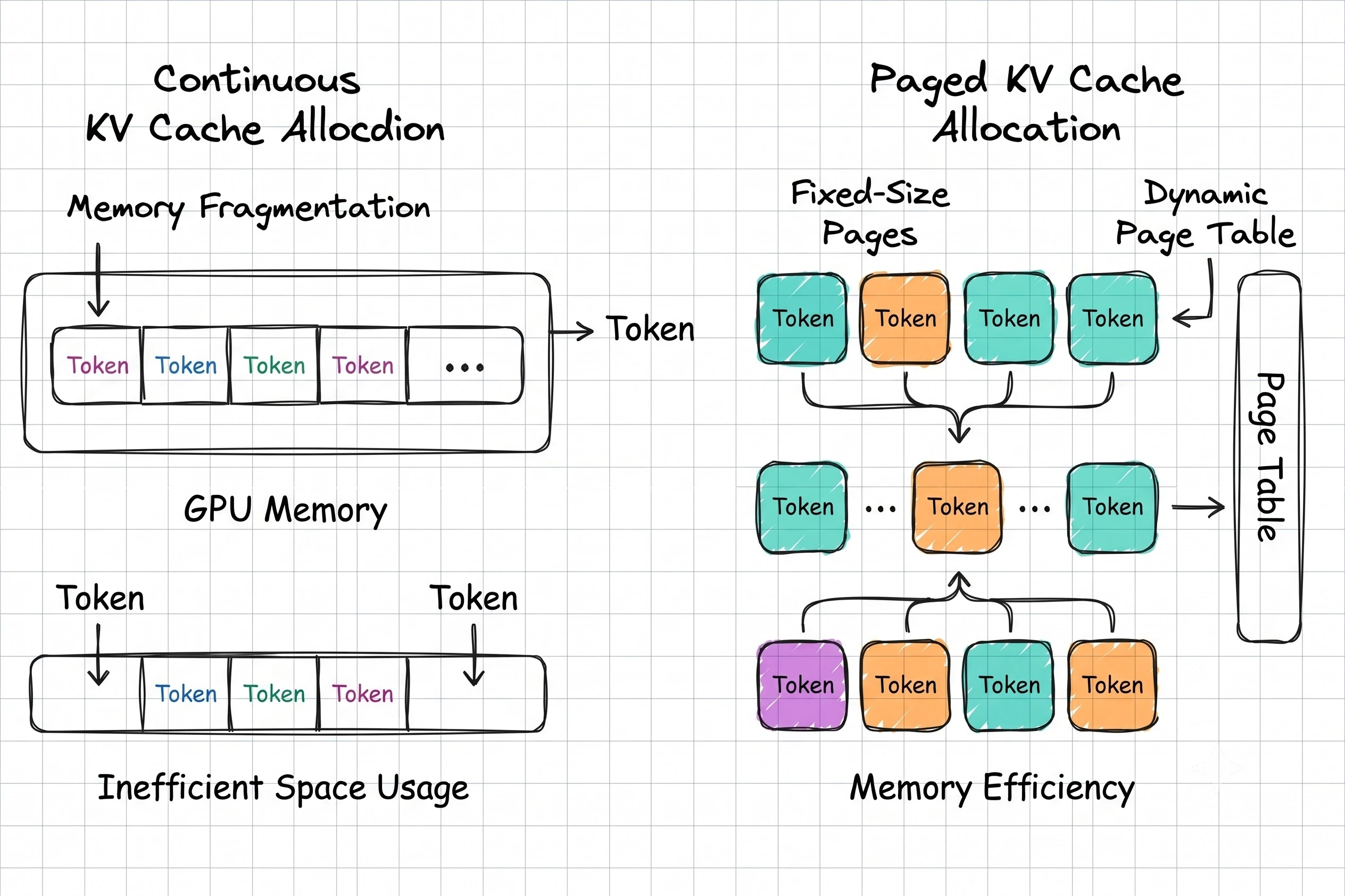
PagedAttention Link to heading
Traditional serving systems allocate memory in large continuous chunks.
This often wastes GPU memory.
PagedAttention treats the KV Cache more like virtual memory.
Instead of requiring large contiguous allocations, memory can be managed in smaller blocks.
The result:
- Better memory utilization
- Less fragmentation
- More concurrent requests
For more details:
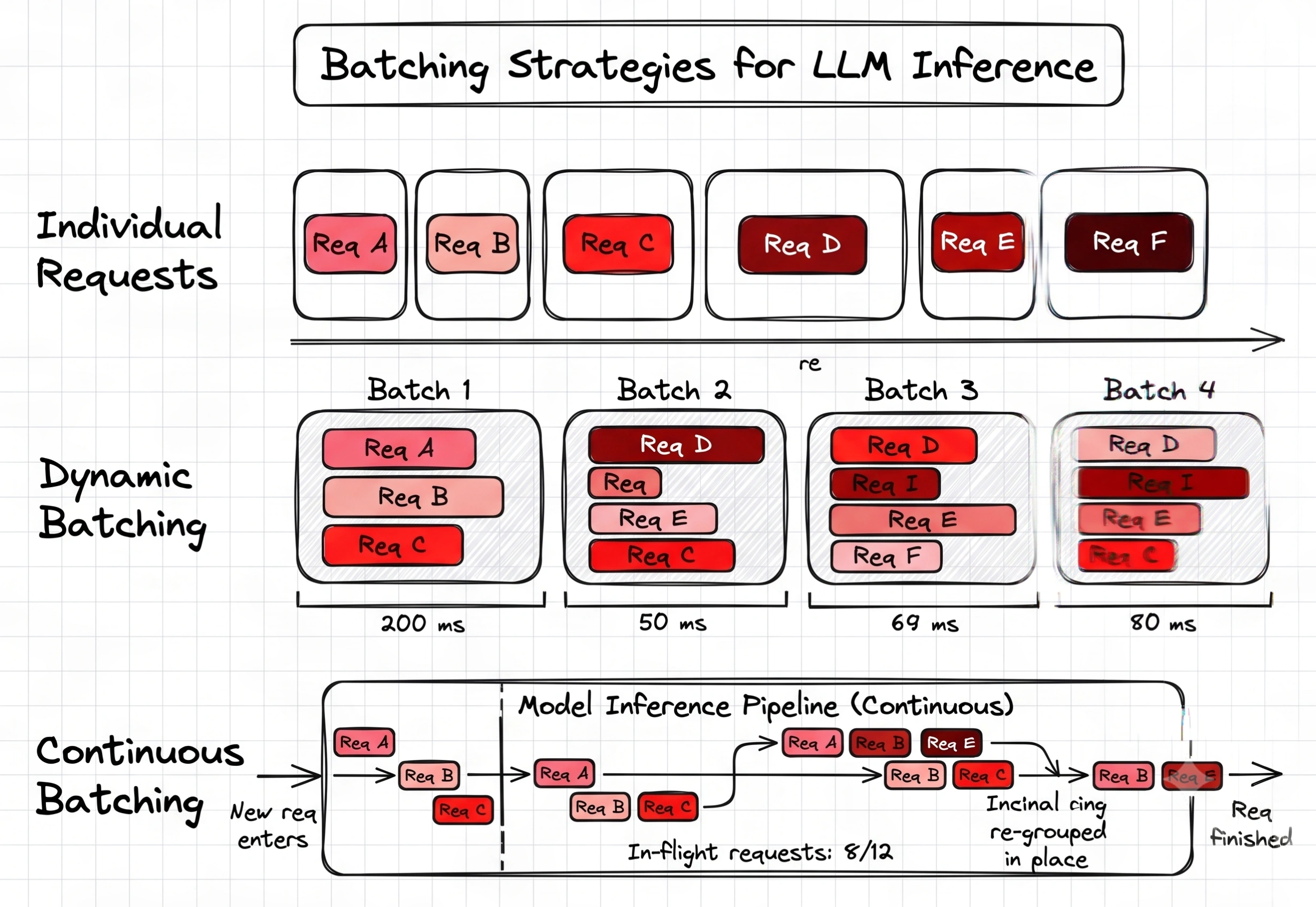
Continuous Batching Link to heading
Another optimization is Continuous Batching.
Traditional batching:
Wait for batch
Process batch
Wait again
vLLM continuously adds new requests as older ones finish.
The GPU stays busy more often.
This improves throughput dramatically.
Why This Matters Link to heading
Suppose you have:
- One expensive GPU
- Hundreds of users
- A production LLM service
The goal isn’t just serving requests.
The goal is serving as many requests as possible without buying more GPUs.
This is fundamentally an infrastructure problem.
Not a machine learning problem.
Where vLLM Fits Link to heading
The stack often looks like:
Users
↓
vLLM
↓
Model
↓
GPU
Or in a Kubernetes environment:
Users
↓
vLLM
↓
Ray / KServe
↓
Kubernetes
↓
GPU Nodes
vLLM focuses on efficient inference.
The layers below focus on orchestration and infrastructure.
Today’s Takeaway Link to heading
Before today, I thought model serving was mostly about exposing an API.
Now I realize the real challenge is GPU efficiency.
vLLM exists because GPUs are expensive.
Techniques like:
- PagedAttention
- Continuous Batching
- Efficient KV Cache management
allow organizations to serve more users with the same hardware.
Tomorrow I’ll put everything together and look at what a modern AI Platform stack actually looks like.