Over the last 6 days, I’ve learned about:
- GPUs
- Kubernetes
- GPU Scheduling
- Ray
- vLLM
Each solved a specific problem.
But I still had a question:
How do all these pieces fit together in a real AI platform?
The answer became much clearer when I stopped looking at individual tools and started looking at the entire system.
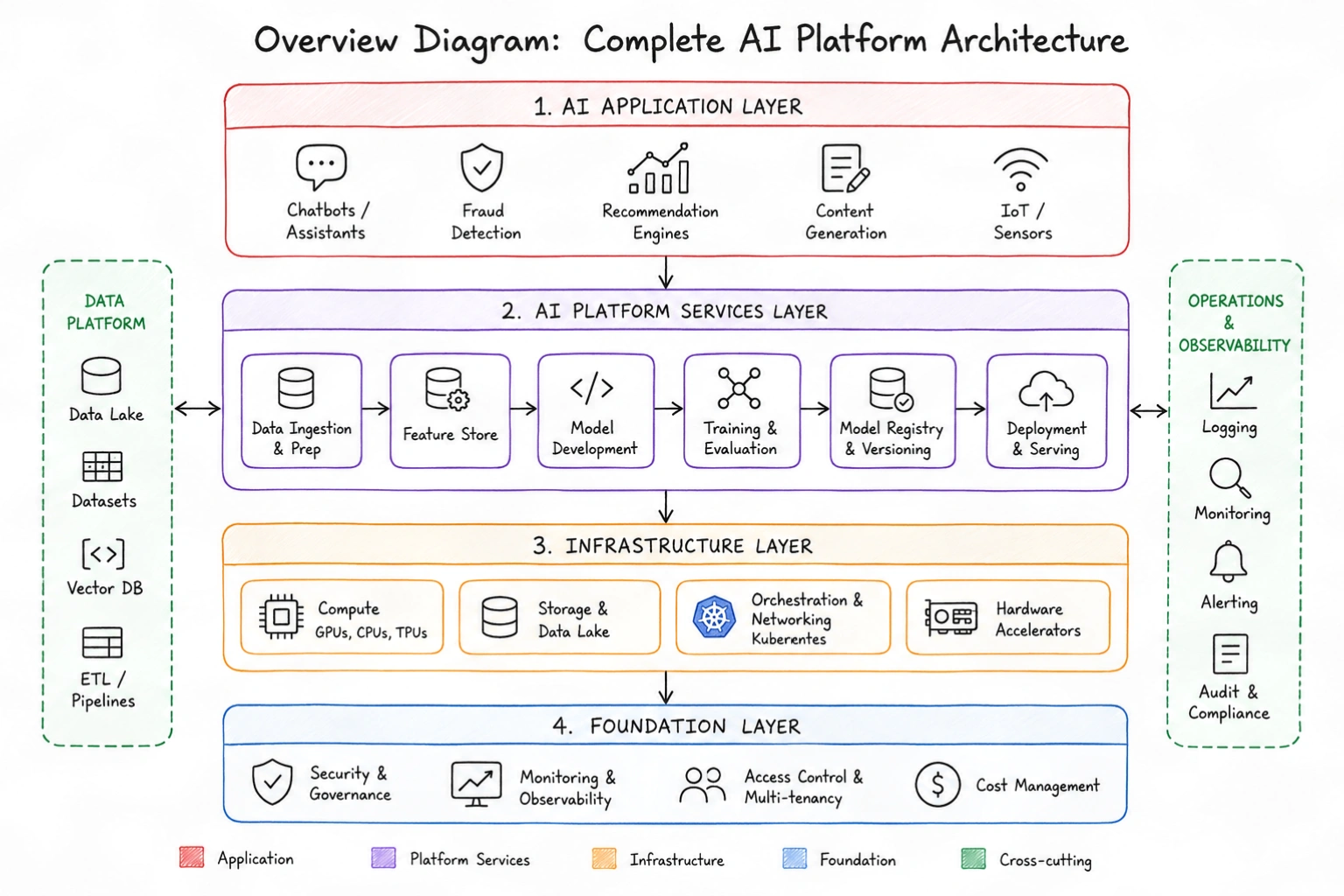
Layer 1: AI Applications Link to heading

At the top are the products users interact with.
Examples:
- Virtual Assistants
- Recommendation Systems
- Fraud Detection
- Content Generation
- IoT Applications
This is the business layer.
Everything below exists to support these applications.
Layer 2: AI Platform Services Link to heading

This is where most AI engineering happens.
The platform is responsible for taking raw data and turning it into production models.
A typical flow looks like:
Data
↓
Feature Engineering
↓
Training
↓
Model Registry
↓
Deployment
↓
Monitoring
Let’s break it down.
Data Processing Link to heading
Every model starts with data.
Teams need to:
- Collect data
- Clean data
- Label data
- Store data
Without good data, nothing else matters.
Feature Engineering Link to heading
Raw data is rarely useful.
Features are created, transformed, and stored for training and inference.
Many organizations use Feature Stores to manage this layer.
Model Training Link to heading
This is where distributed training systems come into play.
This is the part most people associate with AI.
Behind the scenes:
- GPUs
- Scheduling
- Distributed execution
all become important.
Model Registry Link to heading
Once a model is trained:
Where does it live?
Organizations need:
- Versioning
- Metadata
- Reproducibility
Model registries solve this problem.
Deployment & Inference Link to heading
This is where tools like:
- KServe
- Ray Serve
- vLLM
enter the picture.
The goal is simple:
Serve predictions reliably and efficiently.
Monitoring Link to heading
Production models require monitoring just like applications.
Teams track:
- Latency
- Throughput
- Costs
- Data Drift
- Model Performance
A deployed model is not the end of the journey.
It’s the beginning of operating it.
Layer 3: Infrastructure Link to heading

Everything above depends on infrastructure.
This includes:
Compute Link to heading
- CPUs
- GPUs
- TPUs
Storage Link to heading
- Object Storage
- Data Lakes
- Feature Stores
Orchestration Link to heading
- Kubernetes
- Networking
- Scheduling
Accelerators Link to heading
- NVIDIA GPUs
- TPUs
- Specialized Hardware
This was the primary focus of my first 6 days.
Where The Tools Fit Link to heading
One thing I struggled with initially was understanding where different tools belong.
Here’s the mental model I use now:
| Layer | Example Tools |
|---|---|
| Training Pipelines | Kubeflow, Argo Workflows |
| Model Registry | MLflow |
| Distributed Compute | Ray |
| Model Serving | KServe, vLLM |
| Scheduling | Volcano, Kueue |
| Infrastructure | Kubernetes |
| Hardware | GPUs |
No single tool is “the AI platform.”
Each tool solves a specific problem.
What Surprised Me Link to heading
Before starting this series, I thought AI platforms were mostly about machine learning models.
Now I think the harder challenge is everything around the model:
- Infrastructure
- Scheduling
- Training Pipelines
- Deployment
- Monitoring
The model is only one component of the system.
The platform is what makes it usable at scale.
Final Takeaway Link to heading
My biggest takeaway from these 7 days is:
AI Platform Engineering is not a single tool or technology.
It’s the collection of systems that take a model from an experiment to a reliable production service.
Over the last week I focused primarily on the infrastructure side:
- GPUs
- Kubernetes
- Scheduling
- Ray
- vLLM
Next, I want to explore the layer sitting above it:
MLOps.
Questions like:
- How are models trained repeatedly?
- How are experiments tracked?
- How are models versioned?
- How are production models monitored?
That will be the focus of the next learning sprint.
Thanks for following along 🚀